Kubernetes容器编排adm部署 [TOC]
1、kubernetes组件信息 1.1 Master节点组件
*APIServer * :是整个集群的控制中枢,提供集群中各个模块之间的数据交换,并将集群状态和信息存储到分布式键-值(key-value)存储系统Etcd集群中。同时它也是集群管理、资源配额、提供完备的集群安全机制的入口,为集群各类资源对象提供增删改查以及watch的REST API接口。
Scheduler - Scheduler :是集群Pod的调度中心,主要是通过调度算法将Pod分配到最佳的Node节点,它通过APIServer监听所有Pod的状态,一旦发现新的未被调度到任何Node节点的Pod( PodSpec.NodeName为空),就会根据一系列策略选择最佳节点进行调度。Controller Manager :是集群状态管理器,以保证Pod或其他资源达到期望值。当集群中某个Pod的副本数或其他资源因故障和错误导致无法正常运行,没有达到设定的值时,Controller Manager会尝试自动修复并使其达到期望状态。Etcd -Etcd :由Coreos开发,用于可靠地存储集群的配置数据,是一种持久性、轻量型、分布式的键-值(key-value)数据存储组件,作为Kubernetes集群的持久化存储系统。
1.2 Node节点组件
Kubelet :负责与Master通信协作,管理该节点上的Pod,对容器进行健康检查及监控,同时负责玊报节点和节点上面Pod的状态。Kube-Proxy :负责各Pod之间的通信和负载均衡,将指定的流量分发到后端正确的机器上。Runtime:负责容器的管理。CoreDNS :用于Kubernetes集群内部Service的解析,可以让Pod把Service名称解析成Service的IP,然后通过service的IP地址进行连接到对应的应用上。Calico :符合CNI标准的一个网络插件,它负责给每个Pod分配一个不会重复的IP,并且把每个节点当做一各“路由器”,这样一个节点的Pod就可以通过IP地址访问到其他节点的Pod。
2、安装初始化 ⚠️:生产环境当中一般选择3台master。
Master节点和Worker节点的IP地址网段区分开;防止后期由于业务增长,节点资源需要扩充,方便运维管理。
role
ipaddress
configure
k8s-master01(etcd )
192.168.174.110
4 core, 4Gb; 50GBS, CentOS 7.9
k8s-node01
192.168.174.120
4 core, 16Gb; 100GBS, CentOS 7.9
k8s-node02
192.168.174.121
4 core, 16Gb; 100GBS, CentOS 7.9
2.1 所有节点中都需要执行(初始化环境) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 $ systemctl disable --now firewalld NetworkManager $ sed -ri "s/^SELINUX=enforcing/SELINUX=disabled/" /etc/selinux/config $ setenforce 0 $ swapoff -a && sysctl -w vm.swappiness=0 && sed -ri '/^[^#]*swap/s@^@#@' /etc/fstab $ cat <<-EOF >>/etc/hosts 192.168.174.20 k8s-master01 192.168.174.21 k8s-node01 192.168.174.22 k8s-node02 EOF $ curl -o /etc/yum.repos.d/docker-ce.repo https://mirrors.ustc.edu.cn/docker-ce/linux/centos/docker-ce.repo $ sed -i 's#download.docker.com#mirrors.ustc.edu.cn/docker-ce#' /etc/yum.repos.d/docker-ce.repo $ sed -e 's|^mirrorlist=|#mirrorlist=|g' \ -e 's|^#baseurl=http://mirror.centos.org/centos|baseurl=https://mirrors.ustc.edu.cn/centos|g' \ -i.bak \ /etc/yum.repos.d/CentOS-Base.repo $ yum clean all && yum -y install epel-release $ sed -e 's|^metalink=|#metalink=|g' \ -e 's|^#baseurl=https\?://download.fedoraproject.org/pub/epel/|baseurl=https://mirrors.ustc.edu.cn/epel/|g' \ -e 's|^#baseurl=https\?://download.example/pub/epel/|baseurl=https://mirrors.ustc.edu.cn/epel/|g' \ -i.bak \ /etc/yum.repos.d/epel.repo $ cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF $ yum makecache fast cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF $ yum -y update --exclude=kernel* $ yum list docker-ce.x86_64 --showduplicates | sort -r $ yum -y install wget jq psmisc vim net-tools telnet yum-utils \ device-mapper-persistent-data lvm2 git ntpdate \ ipvsadm ipset sysstat conntrack libseccomp \ docker-ce-20.10.* docker-ce-cli-20.10.* containerd $ echo "*/5 * * * * ntpdate -b ntp.aliyun.com" >>/var/spool/cron/root $ ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime $ echo 'ASia/Shanghai' > /etc/tiomezone $ ssh-keygen -t rsa $ for i in k8s-node01 k8s-node02;do ssh-copy-id -i .ssh/id_rsa.pub $i ;done $ cat <<-EOF >>/etc/security/limits.conf * soft nofile 655360 * hard nofile 131072 * soft nproc 655350 * hard nproc 655350 * soft memlock unlimited * hard memlock unlimited EOF $ cat <<-EOF >>/etc/modules-load.d/ipvs.conf ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp ip_vs_sh nf_conntrack ip_tables ip_set xt_set ipt_set ipt_rpfilter ipt_REJECT ipip EOF $ cat <<EOF > /etc/sysctl.d/k8s.conf net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 fs.may_detach_mounts = 1 net.ipv4.conf.all.route_localnet = 1 vm.overcommit_memory=1 vm.panic_on_oom=0 fs.inotify.max_user_watches=89100 fs.file-max=52706963 fs.nr_open=52706963 net.netfilter.nf_conntrack_max=2310720 net.ipv4.tcp_keepalive_time = 600 net.ipv4.tcp_keepalive_probes = 3 net.ipv4.tcp_keepalive_intvl =15 net.ipv4.tcp_max_tw_buckets = 36000 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_max_orphans = 327680 net.ipv4.tcp_orphan_retries = 3 net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_max_syn_backlog = 16384 net.ipv4.ip_conntrack_max = 65536 net.ipv4.tcp_max_syn_backlog = 16384 net.ipv4.tcp_timestamps = 0 net.core.somaxconn = 16384 EOF $ systemctl enable --now docker.service $ cat <<-EOF >/etc/docker/daemon.json { "exec-opts" : ["native.cgroupdriver=systemd" ] } EOF $ systemctl daemon-reload && systemctl restart docker $ yum -y localinstall kernel-m* $ grub2-set-default 0 && grub2-mkconfig -o /etc/grub2.cfg $ grubby --args="user_namespace.enable=1" --update-kernel="$(grubby --default-kernel) " $ reboot
2.2 安装kubernetes组件(v1.23 Master and Node) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ yum list kubeadm.x86_64 --showduplicates | sort -r $ yum install -y kubeadm-1.23* kubelet-1.23* kubectl-1.23* $ yum install -y kubeadm-1.23* kubelet-1.23* $ kubeadm version $ cat <<-EOF >/etc/sysconfig/kubelet KUBELET_EXTRA_ARGS="--cgroup-driver=systemd" EOF $ systemctl enable --now kubelet
⚠️#为什么将kubelet配置成systemd作为cgroug驱动?
2.3 集群初始化 2.3.1 初始化yaml文件(Master01) kubeadm的初始化控制平面(init)命令和加入节点(join)命令均可以通过指定的配置文件修改默认参数的值。kubeadm将配置文件以 ConfigMap形式保存到集群中,便于后续的查询和升级工作。
kubeadm config子命令提供了对这组功能的支持。
kubeadm config print init-defaults:输出kubeadm init命令默认参数的内容。
kubeadm config print join-defaults:输出kubeadm join命令默认参数的内容。
kubeadm config migrate:在新旧版本之间进行配置转换。
kubeadm config images list:列出所需的镜像列表。
kubeadm config images pull:拉取镜像到本地。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 [root@k8s-master01 ~] --- apiVersion: kubeadm.k8s.io/v1beta2 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 192.168.174.110 bindPort: 6443 nodeRegistration: criSocket: /var/run/dockershim.sock name: k8s-master01 taints: - effect: NoSchedule key: node-role.kubernetes.io/master --- apiServer: certSANs: - 192.168.174.110 timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta2 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controlPlaneEndpoint: 192.168.174.110:6443 controllerManager: {} dns: type : CoreDNS etcd: local : dataDir: /var/lib/etcd imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers kind: ClusterConfiguration kubernetesVersion: v1.23.17 networking: dnsDomain: cluster.local podSubnet: 172.168.0.0/16 serviceSubnet: 10.96.0.0/16 scheduler: {} ⚠️:配置文件参数需要修改,修改前备份,或者直接用命令行直接生成新的配置文件,但是仍需要修改配置文件中的参数 [root@k8s-master01 ~] ⚠️配置文件需改参数 advertiseAddress: 192.168.174.140 name: k8s-master01 - 192.168.174.110 controlPlaneEndpoint: 192.168.174.110:6443 imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers kubernetesVersion: v1.23.17 podSubnet: 172.168.0.0/16 serviceSubnet: 10.96.0.0/12 [root@k8s-master01 ~]
2.4 拉取kubernetes组件镜像 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 [root@k8s-master01 ~] [config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.23.17 [config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.23.17 [config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.23.17 [config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.23.17 [config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6 [config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.6-0 [config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.6 [root@k8s-master01 ~] Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME /.kube sudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/config sudo chown $(id -u):$(id -g) $HOME /.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join 192.168.174.140:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:65e8558fcc0d9964de4ce8de880182df2de6e03d6b3402724e35ab7ff8482033 \ --control-plane --certificate-key d4be6bdc8043c565516325e270525e24e7ed6ed6c200f836be2bd52f2ad1ab11 Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward.Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.174.140:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:65e8558fcc0d9964de4ce8de880182df2de6e03d6b3402724e35ab7ff8482033 [root@k8s-master01 ~] [root@k8s-node01 ~] [root@k8s-master01 ~] [root@k8s-master01 ~] [root@k8s-master01 ~] [root@k8s-master01 ~]
kubeadm init命令在执行具体的安装操作之前,会执行一系列被称 为pre-flight checks的系统预检查,以确保主机环境符合安装要求,如果检查失败就直接终止,不再进行init操作。
2.5 Calico网络插件安装(Master01) Calico网站:https://projectcalico.docs.tigera.io
⚠️ :注意kubernetes和calico之间的版本关联;详细信息去官网查看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [root@k8s-master01 ~] [root@k8s-master01 ~] [root@k8s-master01 ~] [root@k8s-master01 ~] [root@k8s-master01 ~] [root@k8s-master01 ~] NAME READY STATUS RESTARTS AGE calico-kube-controllers-6f6595874c-kqvbc 1/1 Running 0 2m15s calico-node-f2kgm 1/1 Running 0 2m15s calico-node-gh9vh 1/1 Running 0 2m15s calico-typha-6b6cf8cbdf-g8cl7 1/1 Running 0 2m15s coredns-65c54cc984-7jp42 1/1 Running 0 11h coredns-65c54cc984-cgcbb 1/1 Running 0 11h etcd-k8s-master01 1/1 Running 1 (5m20s ago) 11h kube-apiserver-k8s-master01 1/1 Running 1 (5m20s ago) 11h kube-controller-manager-k8s-master01 1/1 Running 1 (5m20s ago) 11h kube-proxy-rpp8q 1/1 Running 1 (5m17s ago) 11h kube-proxy-z5p22 1/1 Running 1 (5m20s ago) 11h kube-scheduler-k8s-master01 1/1 Running 1 (5m20s ago) 11h
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@k8s-master01 ~] [root@k8s-master01 ~] - name: CALICO_IPV4POOL_CIDR value: "172.168.0.0/16" Disable file logging so `kubectl logs` works. [root@k8s-master01 ~] [root@k8s-master01 ~]
2.6 生成新的token key值 ⚠️:由于生成的token值有效期较短,或者有新的master或者node节点需要添加集群当中,所以需要获取新的token值
1 2 3 4 5 6 7 8 9 10 11 12 13 $ kubeadm init phase upload-cers --upload-certs $ kubeadm token create --print -join-command $ kubectl get secret -n kube-system bootstrap-token-abcdef $ kubectl get secret bootstrap-token-abcdef -n kube-system -oyaml 找到 expiration: MjAyMi0xMS0yM1QxNDowNjowOFo= $ echo "MjAyMi0xMS0yM1QxNDowNjowOFo=" | base64 --decode
2.7 Metrics server部署(Master01) 在新版的Kubernetes中系统资源的采集均使用Metrics-server,可以通过Metrics采集节点和Pod的内存、磁盘、CPU和网络的使用率。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 [root@k8s-master01 ~] [root@k8s-master01 ~] [root@k8s-master01 kubeadm-metrics-server] [root@k8s-master01 ~] NAME READY STATUS RESTARTS AGE metrics-server-5cf8885b66-8j4nn 1/1 Running 0 46s [root@k8s-master01 ~] NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-master01 295m 7% 1338Mi 34% k8s-node01 140m 3% 782Mi 20% [root@k8s-master01 ~] NAMESPACE NAME CPU(cores) MEMORY(bytes) kube-system calico-kube-controllers-6f6595874c-kqvbc 3m 21Mi kube-system calico-node-f2kgm 56m 109Mi kube-system calico-node-gh9vh 64m 145Mi kube-system calico-typha-6b6cf8cbdf-g8cl7 4m 29Mi kube-system coredns-65c54cc984-7jp42 3m 13Mi kube-system coredns-65c54cc984-cgcbb 3m 16Mi kube-system etcd-k8s-master01 24m 58Mi kube-system kube-apiserver-k8s-master01 104m 325Mi kube-system kube-controller-manager-k8s-master01 28m 57Mi kube-system kube-proxy-rpp8q 1m 18Mi kube-system kube-proxy-z5p22 1m 15Mi kube-system kube-scheduler-k8s-master01 6m 24Mi kube-system metrics-server-5cf8885b66-8j4nn 5m 19Mi
2.8 修改Kube-proxy改为ipvs模式(k8s-master01) 初始化集群的时注释了ipvs配置(Master01),将 kube-proxy 模式从 iptables 修改为 ipvs 是为了提升性能和功能。
详解:
性能优势 :ipvs可以更有效地处理大量并发连接。这使得它在高流量场景下表现更佳。更好地扩展以处理更多的服务和后端 pod,而 iptables 在规则数量非常多时,性能可能会显著下降。低延迟和高吞吐量 :ipvs 通过在内核空间处理数据包,减少了用户空间和内核空间之间的切换,从而提高了数据包处理的效率,带来更低的延迟和更高的吞吐量。快速规则应用 :ipvs 在处理和应用网络规则时速度更快,特别是在规则变更频繁的情况下。多种调度算法 :ipvs 提供了多种负载均衡算法(如轮询、最小连接、最短延迟等),可以根据具体需求选择最合适的算法,而 iptables 则缺乏这种灵活性。稳定性 :ipvs 的实现更加稳定,尤其是在大型集群中,它能更好地应对复杂的网络环境和高负载。简化的规则管理 :ipvs 使用专用的内核模块管理规则,相比 iptables 更加简洁和高效。iptables 规则在处理和管理上会更加复杂,特别是当规则数量增多时。维护方便 :ipvs 的规则结构更清晰,维护起来更为方便,不像 iptables 那样需要处理大量的规则链和复杂的规则匹配逻辑。
1 2 3 4 5 6 7 8 9 10 [root@k8s-master01 ~] [root@k8s-master01 ~] daemonset.apps/kube-proxy patched [root@k8s-master01 ~] ipvs
3、kubernetes常用命令 1.kubectl查看组件主从节点信息(apiserver是无状态的)
1 $ kubectl get leases -n kube-system
2.kubectl创建一个容器
1 $ kubetctl create -f nginx.yaml
3.kubectl查看Pod的状态
1 $ kubectl get po nginx(Pod名称)
4.kubectl run 创建一个Pod
1 $ kubectl run nginx-run --image=nginx:1.21
5.kubectl 查看Pod的IP地址
1 $ kubectl get po nginx -owide
6.kubectl生成一个nginx的yaml文件
1 $ kubectl run nginx --image=nginx:1.21 -oyaml --dry-run > nginx.yaml
7.kubectl 查看pod的apiversion的版本号
1 $ kubectl api-resources | grep pod
8.kubectl查看你kubernetes中的pod
1 $ kubectl get po -n kube-system
9.kubectl查看pod的信息
1 $ kubectl describe po nginx(Pod名称)
10.kubectl查看Pod的日志
1 $ kubectl logs -f nginx(Pod名称) -n kube-system(命名空间)
11.kubectl查看Pod的更新历史
1 $ kubectl rollout history deploy(命名空间) nginx(Pod的名称)--revision=3
3、Kubernetes中Pod概念
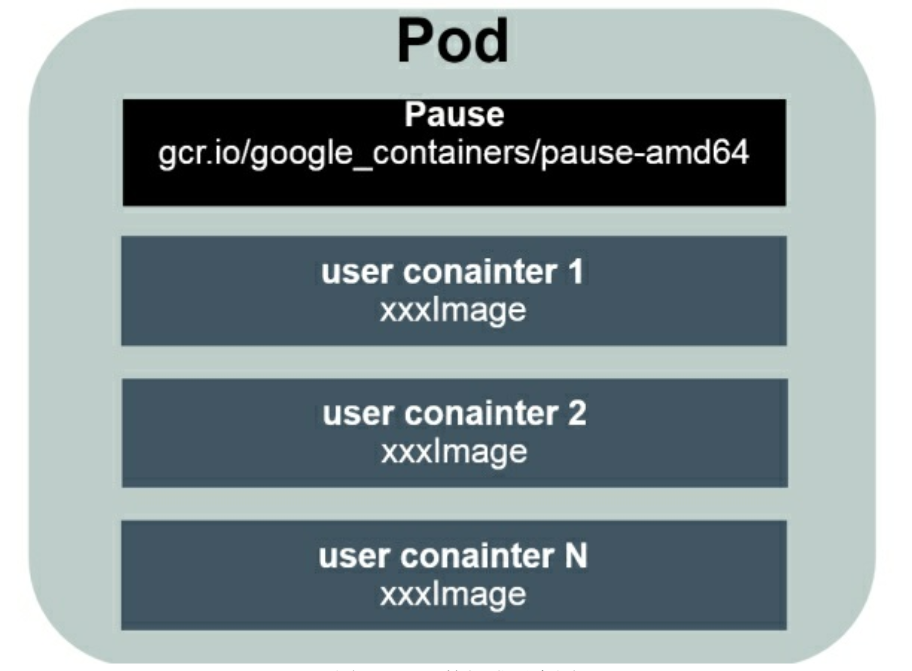
3.1 简介(Pod具有命名空间隔离性) Pod是Kubernetes中最重要的基本概念之一;每个Pod都有一个特殊的被称为“根容器”的Pause容器。Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器,每个Pod都还包含一个或多个紧密相关的用户业务容器。
为什么Kubernetes会设计出一个全新的Pod概念并且Pod有这样特殊的组成结构?
为多进程之间的协作提供一个抽象模型,使用Pod作为基本的调度、复制等管理工作的最小单位,让多个应用进程能一起有效地调度和伸缩。
Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂接的Volume,这样既简化了密切关联的业务容器之间的通信问题,也很好地解决了它们之间的文件共享问题。
Kubernetes为每个Pod都分配了唯一的IP地址,称之为Pod IP,一个 Pod里的多个容器共享Pod IP地址。Kubernetes要求底层网络支持集群内任意两个Pod之间的TCP/IP直接通信,因此在 Kubernetes里,一个Pod里的容器与另外主机上的Pod容器能够直接通信。
3.2 Pod的类型 Pod其实有两种类型:普通的Pod及静态Pod(Static Pod)。后者比较特殊,它并没被存放在Kubernetes的etcd中,而是被存放在某个具体的Node上的一个具体文件中,并且只能在此Node上启动、运行。而普通的Pod一旦被创建,就会被放入etcd中存储,随后被Kubernetes Master 调度到某个具体的Node上并绑定(Binding),该Pod被对应的Node上的 kubelet进程实例化成一组相关的Docker容器并启动。在默认情况下,当Pod里的某个容器停止时,Kubernetes会自动检测到这个问题并且重新启动这个Pod(重启Pod里的所有容器),如果Pod所在的Node宕机,就会将这个Node上的所有Pod都重新调度到其他节点上。
1 2 3 4 5 6 $ ll /etc/kubernetes/manifests/ 总用量 16 -rw------- 1 root root 2328 6月 14 15:57 etcd.yaml -rw------- 1 root root 3395 6月 14 15:57 kube-apiserver.yaml -rw------- 1 root root 2892 6月 14 15:57 kube-controller-manager.yaml -rw------- 1 root root 1477 6月 14 15:57 kube-scheduler.yaml
3.2.1 Pause容器 Pod运行在一个被称为节点 (Node)的环境中,这个节点既可以是物理机,也可以是私有云或者公有云中的一个虚拟机,在一个节点上能够运行多个Pod;其次,在每个Pod中都运行着一个特殊的被称为Pause的容器,其他容器则为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷,因此它们之间的通信和数据交换更为高效,在设计时我们可以充分利用这一特性将一组密切相关的服务进程放入同一个Pod中;但不推荐。用pause镜像为每个Pod都创建一个容器。该Pause容器用于接管Pod中所有其他容器的网络。每创建一个新的Pod,kubelet 都会先创建一个Pause容器,然后创建其他容器。pause镜像大概有200KB,是个非常小的容器镜像。
举例:
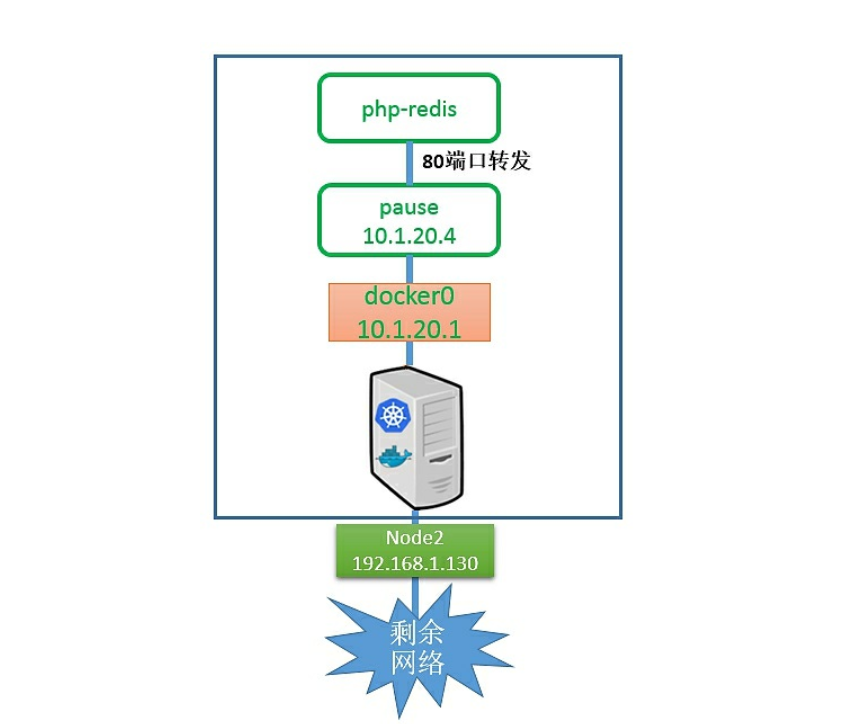
首先,一个Pod内的所有容器都需要共用同一个IP地址,这就意味着一定要使用网络的容器映射模式。然而,为什么不能只启动1个容器,而将第2个容器关联到第1个容器呢?Kubernetes是从两方面来考虑这个问题的:首先,如果在Pod内有多个容器,则可能很难连接这些容器;其次,后面的容器还要依赖第1个被关联的容器,如果第2个容器关联到第1个容器,且第1个容器死掉的话,那么第2个容器也将无法正常提供服务。启动一个基础容器,然后将Pod内的所有容器都连接到它上面会更容易一些。因为我们只需为基础的pause容器执行端口映射规则,这也简化了端口映射的过程。
上图有点儿取巧地显示了是pause容器将端口80的流量转发给了相关容器。而Pause容器只是看起来转发了网络流量,但它并没有真的这么做。实际上,应用容器直接监听了这些端口,和pause容器共享同一个网络堆栈。
3.2.2 静态Pod 静态Pod是由kubelet进行管理的仅存在于特定Node上的Pod。它们不能通过API Server进行管理,无法与ReplicationController、Deployment 或者DaemonSet进行关联,并且kubelet无法对它们进行健康检查。静态Pod总是由kubelet创建的,并且总在kubelet所在的Node上运行。
3.3 定义一个Pod 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 $ kubectl run test --image=registry.cn-hangzhou.aliyuncs.com/hujiaming/nginx:1.24.0 pod/nginx created $ kubectl run nginx --image=registry.cn-hangzhou.aliyuncs.com/hujiaming/nginx:1.24.0 -oyaml --dry-run=client > test -pod.yaml $ vim test -pod.yaml --- apiVersion: v1 kind: Pod metadata: labels: run: nginx name: nginx spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/hujiaming/nginx:1.24.0 name: nginx restartPolicy: Always $ kubectl apply -f test -pod.yaml $ kubectl describe po nginx $ kubectl get po NAME READY STATUS RESTARTS AGE nginx 1/1 Running 0 4m10s $ kubectl delete po nginx pod "nginx" deleted $ kubectl delete -f <Pod资源清单/yaml文件> $ kubectl api-resources
3.4 Kubernetes修改Pod内容器的启动命令 简介:覆盖容器的默认启动命令。重新定义容器的启动命令或者添加新的参数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 $ vim test -pod.yaml --- apiVersion: v1 kind: Pod metadata: labels: run: nginx name: nginx spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/hujiaming/nginx:1.24.0 name: nginx command : ['ls' ,'/' ] ports: - containerPort: 80 $ kubectl create -f test -pod.yaml $ kubectl get po -owide
1 2 3 $ curl 172.16.32.131 curl: (7) Failed connect to 172.16.32.131:80; 拒绝连接
思考题:为什么修改了容器的默认启动命令后,容器无法正常启动,且状态变成了CrashLoopBackOff
3.5 Pod的创建过程
用户通过 kubectl 命令行工具、Kubernetes API 或其他工具提交 Pod 定义(通常是一个 YAML 文件)给 Kubernetes 集群。
用户提交的 Pod 定义被发送到 Kubernetes API Server。
API Server 验证请求并将其存储在 etcd 中。
Scheduler 监视 etcd 中的新建 Pod 事件,并决定将 Pod 分配到哪个节点上运行。调度器考虑多种因素,包括资源需求、节点容量、节点健康状态、亲和性和反亲和性规则等。
调度器将调度决定(即 Pod 应该运行在哪个节点上)写回到 API Server,API Server 更新 etcd 中的 Pod 状态,将其绑定到指定节点。
每个节点上运行的 Kubelet 组件监视 etcd 中分配到该节点的 Pod。Kubelet 检测到新分配的 Pod 后,开始创建和管理 Pod 中的容器。
Kubelet 使用容器运行时(如 Docker、containerd 等)来拉取指定的镜像,并在节点上启动容器。
在启动容器时,Kubelet 会配置网络设置(通过 CNI 插件),挂载卷,并根据 Pod 定义的配置(如环境变量、ConfigMap、Secret 等)初始化容器。
如果 Pod 定义中配置了探针(LivenessProbe、ReadinessProbe),Kubelet 会定期执行这些探针来检测容器的健康状态。
容器启动并运行后,Kubelet 会持续监视容器的状态,并报告给 API Server。Kubelet 还会处理探针检测结果,根据需要重启容器或将其从服务负载均衡中移除。
整个过程中,Kubelet 不断地将容器的状态(如运行状态、资源使用情况、探针检测结果等)更新到 API Server,API Server 再将这些状态更新存储到 etcd 中。
3.6 Pod的删除过程
用户通过 kubectl 命令行工具、Kubernetes API 或其他工具提交删除 Pod 的请求。
删除请求被发送到 Kubernetes API Server,API Server 验证并处理该请求。
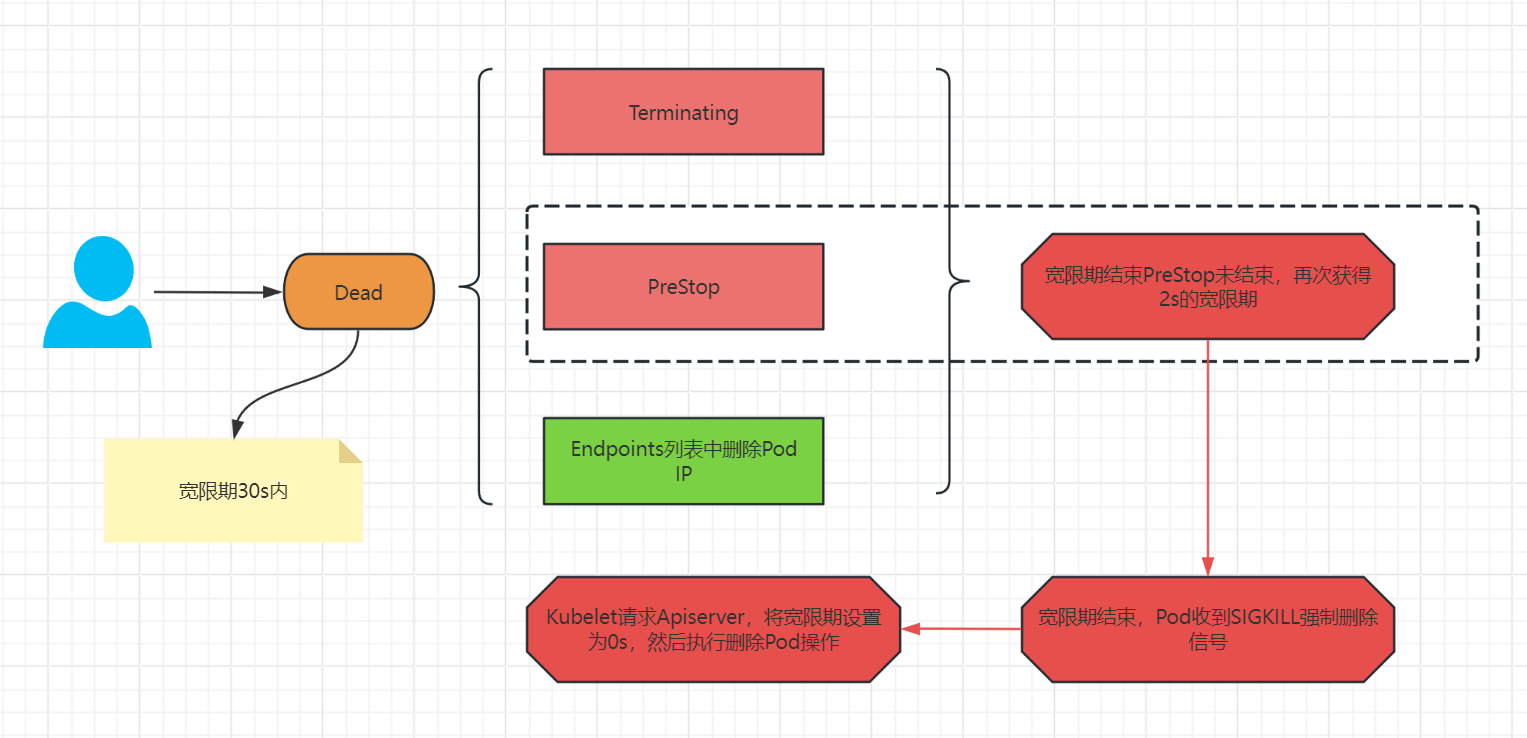
API Server 将 Pod 的状态更新为 Terminating 并存储到 etcd 中。此时,Pod 仍然存在,但其状态表明正在进行删除操作。
如果 Pod 配置了 PreStop 钩子,Kubelet 会在终止容器前执行该钩子。PreStop 钩子可以是一个在容器内运行的命令或发送到指定 HTTP 端点的请求。
如果 Pod 配置了 Readiness 探针,Kubernetes 会将其从服务负载均衡器中移除,确保不再接受新的请求。
Kubelet 发送信号(如 SIGTERM)给容器,通知其终止进程。Kubelet 等待一段时间(由 terminationGracePeriodSeconds 定义,默认为 30 秒)以允许容器进行清理和优雅关闭。
如果容器在优雅终止期内未能退出,Kubelet 会发送强制终止信号(如 SIGKILL)来强制终止容器。
Kubelet 调用容器运行时(如 Docker、containerd 等)删除容器。容器的所有资源(如文件系统、网络等)也会被清理。
Kubelet 更新 Pod 的状态为已删除,并通知 API Server。API Server 将 Pod 的最终状态存储到 etcd 中。
API Server 从 etcd 中删除 Pod 的定义和状态信息。此时,Pod 从 Kubernetes 集群中完全消失。
4、kubernetes中Pod的各种状态
Pending :Pod 已被 Kubernetes系统接收,但仍有一个或多个容器未被创建,可以通过kubectl describe查看处于Pending状态的原因(有可能请求的资源过大,无法调度;有可能挂载的东西不存在;有可能没有可用的节点;有可能节点异常)
Running :Pod已经被绑定到一个节点上,并且所有的容器都已经被创建,而且至少有一个是运行状态,或者是正在启动或者重启,可以通过kubectl logs查看Pod的日志。
Failed :所有容器都已终止,并且至少有一个容器以失败的方式终止,也就是说这个容器要么以非零状态退出,要么被系统终止,可以通过logs和 describe查看Pod日志和状态
Succeeded :所有容器执行成功并终止,并且不会再次重启,可以通过kubectl logs查看Pod日志
Unknown :通常是由于通信问题造成的无法获得Pod的状态
ImagePullBackOff ErrlmagePull: 镜像拉取失败,一般是由于镜像不存在、网络不通或者需要登录认证引起的,可以使用describe命令查看具体原因
CrashLoopBackOff :容器启动失败,可以通过logs命令查看具体原因,一般为启动命令不正确,健康检查不通过等
OOMKilled :容器内存溢出,一般是容器的内存Limit设置的过小,或者程序本身有内存溢出,可以通过logs查看程序启动日志
Terminating :Pod正在被删除,可以通过describe查看状态
SysctlForbidden :Pod自定义了内核配置,但 kubelet 没有添加内核配置或配置的内核参数不支持,可以通过describe查看具体原因
Completed :容器内部主进程退出,一般计划任务执行结束会显示该状态,此时可以通过 logs查看容器日志
ContainerCreating :Pod 正在创建,一般为正在下载镜像,或者有配置不当的地方,可以通过describe查看具体原因。
5、kubernetes中Pod的镜像拉取策略 5.1 简介 在 Kubernetes 中,镜像拉取策略(Image Pull Policy)决定了 Kubernetes 节点如何从镜像仓库中拉取容器镜像策略。
通过spec.containers[].imagePullPolicy参数可以指定镜像的拉取策略(latest为最新版本镜像)
Always :总是拉取,每次创建Pod 时,Kubernetes 都会尝试从镜像仓库中拉取镜像。当镜像 tag为latest时,且imagePullPolicy未配置,默认为Always。适用于开发环境中频繁更新的镜像。Never :不管本地是否存在镜像都不会拉取。必须保证节点上已经存在所需的镜像。否则Pod启动失败。IfNotPresent :指定镜像版本在本地不存在时才去拉取镜像,如果tag为非latest,且 imagePullPolicy未配置,默认为IfNotPresent。
5.2 更改镜像拉取策略为lfNotPresent 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@k8s-master01 ~] [root@k8s-master01 imagePull] --- apiVersion: v1 kind: Pod metadata: name: nginx-study spec: containers: - name: nginx-study image: registry.cn-hangzhou.aliyuncs.com/hujiaming/nginx:1.24.0 imagePullPolicy: IfNotPresent ports: - containerPort: 80 [root@k8s-master01 imagePull] [root@k8s-master01 imagePull]
5.3 更改镜像拉取策略为Always 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [root@k8s-master01 imagePull] pod "nginx-study" deleted [root@k8s-master01 imagePull] --- apiVersion: v1 kind: Pod metadata: name: nginx-study spec: containers: - name: nginx-study image: registry.cn-hangzhou.aliyuncs.com/hujiaming/nginx:1.24.0 imagePullPolicy: Always ports: - containerPort: 80 [root@k8s-master01 imagePull] pod/nginx-study created [root@k8s-master01 imagePull]
5.4 更改镜像拉取策略为Never 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 [root@k8s-master01 imagePull] pod "nginx-study" deleted [root@k8s-master01 imagePull] --- apiVersion: v1 kind: Pod metadata: name: nginx-study spec: containers: - name: nginx-study image: registry.cn-hangzhou.aliyuncs.com/hujiaming/nginx:1.24.0 imagePullPolicy: Never ports: - containerPort: 80 [root@k8s-master01 imagePull] pod/nginx-study created [root@k8s-master01 imagePull] NAME READY STATUS RESTARTS AGE nginx-study 0/1 ErrImageNeverPull 0 4s [root@k8s-master01 imagePull]
6、kubernetes中Pod的重启策略 6.1 简介 在 Kubernetes 中,Pod 的重启策略(Restart Policy)定义了 Pod 中的容器在失败或终止后的重启行为。
可以使用spec.restartPolicy指定容器的重启策略操作方式(Always生产环境居多)
AlwaysOnFailure :当容器以非零退出码(表示失败)终止时,Kubernetes 才会重启容器。Never :容器终止后不会被重启。
6.2 指定重启策略为Always: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 [root@k8s-master01 ~]# mkdir restartPoilcy [root@k8s-master01 restartPolicy]# vim nginx-always.yaml --- apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - name: nginx image: registry.cn-hangzhou.aliyuncs.com/hujiaming/nginx:1.24.0 imagePullPolicy: IfNotPresent command: - sleep - "10" ports: - containerPort: 80 restartPolicy: Always [root@k8s-master01 restartPolicy]# kubectl create -f nginx-always.yaml [root@k8s-master01 restartPolicy]# kubectl get po NAME READY STATUS RESTARTS AGE nginx 0 /1 CrashLoopBackOff 6 (21s ago) 7m33s [root@k8s-master01 restartPolicy]# kubectl describe po nginx
6.3 指定重启策略为OnFailure: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 [root@k8s-master01 ~] pod "nginx" deleted [root@k8s-master01 restartPolicy] --- apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - name: nginx image: registry.cn-hangzhou.aliyuncs.com/hujiaming/nginx:1.24.0 imagePullPolicy: IfNotPresent command : - sleep - "10" ports: - containerPort: 80 restartPolicy: OnFailure [root@k8s-master01 restartPolicy] pod/nginx created [root@k8s-master01 restartPolicy] NAME READY STATUS RESTARTS AGE nginx 0/1 Completed 0 14s [root@k8s-master01 restartPolicy]
思考题:为什么查看Pod的状态的时候是Completed,但是kubernetes却没有重启该Pod呢?
6.4 指定重启策略为Never: 略
7、kubernetes中Pod的健康检查
7.1 简介 在 Kubernetes 中,探针(Probe)用于检测 Pod 中容器的健康状态和生命周期管理。探针可以帮助 Kubernetes 确保应用程序在运行中的健康状态,并在需要时采取适当的动作(如重启容器、将流量切换到健康的容器等)。Kubernetes对Pod的健康状态可以通过三类探针来检查:LivenessProbe、ReadinessProbe及StartupProbe,其中最主要的探针为 LivenessProbe与ReadinessProbe,kubelet会定期执行这两类探针来诊断容器的健康状况。
7.2 Pod的探针
StartupProbe :用于判断容器内应用程序是否已经启动。某些应用会遇到启动比较慢的情况,例如应用程序启动时需要与远程服务器建立网络连接,或者遇到网络访问较慢等情况时,会造成容器启动缓慢, 因为这属于“有且仅有一次”的超长延时,可以通过StartupProbe探针解决该问题。如果配置了startupProbe,就会先禁止其他的探针,直到它成功为止,成功后将不在进行探测。如果探针失败,kubelet则杀死容器,并且按照预先在资源清单中设定的重启策略重启容器。
LivenessProbe :用于探测容器是否运行,如果探测失败,kubelet会根据配置的重启策略进行相应的处理。若没有配置该探针,默认就是success。(存活探针,探针失败;按照预先在资源清单中设定的重启策略重启容器)
ReadinessProbe :用于判断容器服务是否可用(Ready状态),达到Ready状态的Pod才可以接收请求。并且程序已经是可以接受流量的状态。对于被Service管理的 Pod,Service与Pod Endpoint的关联关系也将基于Pod是否Ready进行设置。如果在运行过程中Ready状态变为False,则系统自动将其从Service 的后端Endpoint列表中隔离出去,后续再把恢复到Ready状态的Pod加回后端Endpoint列表。这样就能保证客户端在访问Service时不会被转发到服务不可用的Pod实例上。需要注意的是,ReadinessProbe也是定期触发执行的,存在于Pod的整个生命周期中。(就绪探针,探针失败不会重启pod )
7.2.1 StartupProbe和LivenessProbe的区别 StartupProbe 用于检测容器的启动是否完成,特别适用于启动时间较长的应用程序。在应用程序启动时间较长,可能超过默认的 LivenessProbe 超时时间,以防止应用程序在启动过程中被误判为不健康并被杀死。而StartupProbe 可以预先设置推迟存活检测时间,如果配置了 StartupProbe ,在其成功之前,LivenessProbe 将被禁用。一旦 StartupProbe 成功,LivenessProbe 开始工作。如果 StartupProbe 失败,容器将被重启。其中最重要的一个作用StartupProbe在第一次探针完成后后续将不再执行探针,但是LivenessProbe将在容器的整个生命周期循环执行。
StartupProbe :专注于应用程序启动阶段,防止应用程序启动时间较长时被误判为不健康。
LivenessProbe :专注于应用程序的运行阶段,确保应用程序在运行过程中保持健康。
7.3 Pod的四种探针方式(HTTPGetAction建议生产使用)
ExecActionTCPSocketActionHTTPGetActiongRPC探针:1.24版本之后开启
7.3.1 LivenessProbe和ReadinessProbe探针配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 [root@k8s-master01 ~]# mkdir probe && cd probe/ --- apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/hujiaming/nginx:1.24.0 name: nginx readinessProbe: httpGet: path: /index.html port: 80 scheme: HTTP initialDelaySeconds: 15 timeoutSeconds: 3 periodSeconds: 15 successThreshold: 1 failureThreshold: 2 livenessProbe: tcpSocket: port : 80 initialDelaySeconds: 15 timeoutSeconds: 3 periodSeconds: 15 successThreshold: 1 failureThreshold: 2 command: - sh - -c - sleep 30 ;nginx -g "daemon off;" restartPolicy: Always [root@k8s-master01 probe]# kubectl create -f nginx-probe.yaml
7.3.2 StartupProbe探针配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 --- apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: imagePullPolicy: IfNotPresent - image: registry.cn-hangzhou.aliyuncs.com/hujiaming/nginx:1.24.0 name: nginx startupProbe: tcpSocket: port: 80 initialDelaySeconds: 10 timeoutSeconds: 2 periodSeconds: 10 successThreshold: l failureThreshold: 2 readinessProbe: httpGet: path: /index.html port: 80 initialDelaySeconds: 10 timeoutSeconds: 2 periodSeconds: 10 successThreshold: 1 failureThreshold: 2 livenessProbe: tcpSocket: port: 80 initialDelaySeconds: 10 timeoutSeconds: 2 periodSeconds: 10 successThreshold: 1 failureThreshold: 2 command: - sleep - "10" ports: - containerPort: 80 restartPolicy: Always
8、Pod平滑退出配置 倒钩
kubernetes默认设置Pod退出宽限期为30s,但也可以自定义。配置代码处如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 --- apiVersion: v1 kind: Pod metadata: name: nginx namespace: default spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/hujiaming/nginx:1.24.0 imagePullPolicy: IfNotPresent lifecycle: postStart: exec: command: - sh - -c - mkdir /data/ preStop: exec: command: - sh - -c - sleep 10 name: nginx ports: - containerPort: 80 protocol: TCP restartPolicy: Never terminationGracePeriodSeconds: 30
当 Kubernetes 终止一个 Pod 时,会触发 PreStop 钩子,同时开始计时宽限期(例如 30 秒)。
容器会接收到 SIGTERM 信号,进入关闭状态,同时 Kubernetes 等待容器的正常退出。
如果 Pod 在宽限期内(30 秒)完成了生命周期钩子的执行并干净地关闭了,那么 Pod 将被成功终止。
如果宽限期到达时,Pod 仍然没有停止,将会再次的得到2s的宽限期。2s后,Kubernetes 将发送 SIGKILL 信号,强制终止 Pod。
8.1 简介 在 Kubernetes 中,preStop 钩子是 Pod 生命周期管理的一部分。它允许你在容器终止之前运行一个命令或脚本,用于优雅地关闭服务、关闭连接或清理资源。preStop 钩子是在 Pod 中定义的生命周期钩子之一。当容器收到终止信号时,preStop 钩子会在容器实际终止前执行。
8.2 PreStop钩子配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 [root@k8s-master01 ~] --- apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - name: nginx image: registry.cn-hangzhou.aliyuncs.com/hujiaming/nginx:1.24.0 imagePullPolicy: IfNotPresent lifecycle: postStart: exec : command : - sh - -c - 'mkdir /data/' preStop: exec : command : - sh - -c - psleep 10 ports: - containerPort: 80 restartPolicy: Never [root@k8s-master01 ~] pod/nginx created [root@k8s-master01 ~] NAME READY STATUS RESTARTS AGE nginx 1/1 Running 0 6s [root@k8s-master01 ~] [root@k8s-master01 ~] NAME READY STATUS RESTARTS AGE nginx 1/1 Terminating 0 22s [root@k8s-master01 ~]
注意:在容器创建之后,容器的Entrypoint执行之前,这时候Pod已经被调度到某台node上,被某个 kubelet管理了,这时候kubelet会调用postStart操作,该操作跟容器的启动命令是在同步执行的,也就是说在postStart操作执行完成之前,kubelet会锁住容器,不让应用程序的进程启动,只有在 postStart操作完成之后容器的状态才会被设置成为RUNNING。













/kubernetes 二进制高可用安装部署(v1.23+)/1.png)


